Vector Embeddings, Explained
ChatGPT is probably the most tried AI tool, and it’s also the most powerful. If you’ve been living under a rock and haven’t heard of this weird entity, I’ll explain it to you.
ChatGPT, Bard, and BingAI (also backed by GPT) are natural language processing (NLP) tools driven by AI technology that allow you to engage in human-like conversations and much more with the chatbot. To put it simply, they’re the closest things we have to talking to a robot/machine just as naturally as we talk to a human being.
It’s not just for having a random chat, but it can also solve many problems, such as helping you with coding, writing letters, understanding the context of given inputs or documents, creating summaries, and so on. Now, you might wonder how this thing can perform all these tasks, sometimes even better than a human can. The answer is simple: LLM.
What the heck is LLM?
LLM stands for Large Language Model, a new (actually not so new) computer program that can comprehend human language, including words, sentences, and even paragraphs, and generate new text based on the given inputs.
Understanding and generation are the two primary purposes of LLM. So, how does LLM understand and generate language, especially human language, given that computers don’t actually speak our language, right?
This is where vector embeddings come into play. What the heck is that? Easy, I will explain it to you.
Vector Embeddings
A vector is simply a mathematical representation of something — yes, something. It could be text, an image, a video, or even a document. Why do we need vectors? Like I mentioned earlier, it’s because computers don’t speak human language; they only understand numbers (yeah, computers are nerds 🤓).
Vectors can help computers understand things that only humans can comprehend, such as text. Therefore, vectorization involves converting any type of data into vector data. If a vector is the mathematical representation of something, then what’s the purpose of embeddings? Allow me to explain it as gently as I can.
A vector is essentially unstructured data within a computer’s system. Even after you’ve vectorized something to enabling the computer to read it to some extent, the computer still can’t grasp the meaning of it. For instance, if you vectorize a word like “eating” into a 2-dimensional matrix such as [2.3, 3.6], the computer still doesn’t understand the significance of [2.2, 3.6]. It remains merely a representation, but still meaningless. That’s why we need embeddings, to give the meaning of that representation so the computer can understand it.
But, how does it work?
The embedding uses various techniques like neural network or co-occurrence statistics to derive the mathematical representation for words based on their usage in given corpus of text.
Let’s use an example!
Disclaimer: This is merely an example illustrating how embedding functions, without using a specific approach. Thus, it may not be entirely accurate, but it should give you an understanding of its functionality. 🙏
Training
We’ll use just two sentences to train our so-called embedding model. Here are the sentences we’ll use:
- I want to eat pizza.
- I love you.
From the provided minimal data, we’ll break down the sentences into word pieces, which we refer to as tokens. Tokenized sentences will appear as follows:
- [“I”, “want”, “to”, “eat”, “pizza”]
- [“I”, “love”, “you”]
Afterward, we’ll convert each token into a vector. For the purposes of this article, I’ll assign a random 2-dimensional matrix. In a real scenario, we would use a higher-dimensional matrix to enhance expressiveness, feature representations, separability, and so on.
- “I”: [0.2, 0.3]
- “want”: [0.1, 0.25]
- “to”: [0.15, 0.35]
- “eat”: [0.18, 0.28]
- “pizza”: [0.22, 0.38]
- “love”: [0.32, 0.15]
- “you”: [0.28, 0.12]
Yes, we don’t use the same word twice. Once we’ve vectorized the sentences, the embedding model will employ statistical approaches to identify relations or neighbors between the words. Put simply, it will learn how each word relates to the others.

If the model fits successfully, we can use this model for various use cases, like vector search and similarity. We can even apply it in generative AI to create new data points based on the relationships between the vectors.
Vector similarity
We’ll attempt to calculate the similarity of the new input with the data inside the model. In this example, I’ll use the sentence “I love pizza” as our new input.
Similarity between “I love pizza” and “I want to eat pizza”:
- Vectorize it
- “I”: [0.2, 0.3]
- “want”: [0.1, 0.25]
- “to”: [0.15, 0.35]
- “eat”: [0.18, 0.28]
- “pizza”: [0.22, 0.38]
- “love”: [0.32, 0.15]
2. Calculate the mean vector
- I love pizza = [(0.2+0.32+0.22)/3, (0.3+0.15+0.38)/3] = [0.24667, 0.27667]
- I want to eat pizza = [(0.2+0.1+0.15+0.18+0.22)/5,(0.3+0.25+0.35+0.28+0.38)/5] = [0.19, 0.31]
3. Calculate the cosine similarity
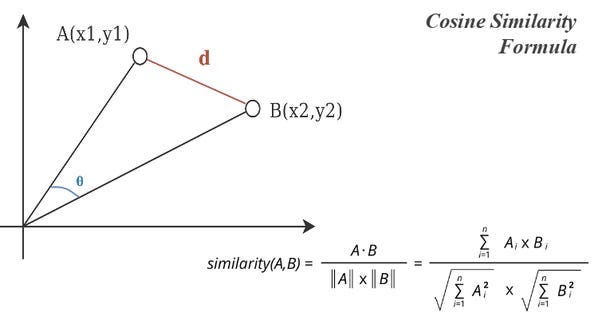
Cosine similarity = (0.19*0.24667)+(0.31*0.27667)/sqrt(0.19²+0.13²)*sqrt(0.24667²+0.27667²)
Cosine similarity = 0.0466987/0.3800244 = 0.12313
So, the cosine similarity between “I want to eat pizza” and “I love pizza” is approximately 0.12313.
Similarity between “I love pizza” and “I love you”:
- Vectorize it
- “I”: [0.2, 0.3]
- “love”: [0.32, 0.15]
- “pizza”: [0.22, 0.38]
- “you”: [0.28, 0.12]
2. Calculate the mean vector
- I love pizza = [(0.2+0.32+0.22)/3, (0.3+0.15+0.38)/3] = [0.24667, 0.27667]
- I love you = [(0.2+0.32+0.28)/3, (0.3+0.15+0.12)/3] = [0.26667, 0.19]
3. Calculate the cosine similarity
Cosine similarity = (0.24667*0.26667)+(0.27667*0.19)/sqrt(0.24667²+0.27667²)*sqrt(0.26667²+0.19²)
Cosine similarity =0.134464/0.319405= 0.42083
So, the cosine similarity between “I love pizza” and “I love you” is approximately 0.42083.
Cosine similarity calculates the cosine of the angle between two vectors. The closer the cosine similarity is to 1, the more similar the vectors (and thus the sentences) are. In the case above, we could conclude that “I love pizza” is closer to “I love you” than to “I want to eat pizza.” However, we understand that in the context of human language, “I love pizza” is likely closer to “I want to eat pizza.” Due to our limited training data and minimal vector representation, the calculation isn’t highly accurate.
Once again, the example in this article is a simplified representation, and the actual workings of embedding are far more intricate. I’ve simplified the process to aid in understanding. For a deeper exploration, feel free to explore my repository: https://github.com/jerichosiahaya/vector-similarity.
Exploring the repository will provide you with a deeper understanding of how vector similarity works. On that repository, I use Indonesian fine-tuned BERT version, as the embedding model and CTranslate2 as the inference engine. For those interested, the model can be downloaded from this link: https://huggingface.co/jerichosiahaya/indobert-base-uncased-ct2.
Conclusion
- Understanding and generation are the two primary purposes of Large Language Model (LLM).
- Vector is a mathematical representation of information such as text, image, and video.
- Vector similarity could be used in various use cases such as classification, sentiment analysis, recommendation systems, and object detection.
- Generative AI, a prominent trend in the AI field, utilizes the same embedding system to create new data points that can be transformed into real human context information such as text, images, or videos.
